دیتا کاتالوگ چیست؟
دیتا کاتالوگ (Data Catalog) یک ابزار است که به سازمانها کمک میکند تا دادههای خود را بهطور منظم و سازمانیافته ذخیره، شناسایی و مدیریت ک�نند. این کاتالوگ میتواند شامل متادیتا (اطلاعات اضافی درباره دادهها) باشد که به کاربران این امکان را میدهد بهراحتی به دادهها دسترسی پیدا کنند، کیفیت دادهها را ارزیابی کنند، و از آنها در تصمیمگیریهای خود استفاده کنند.
از ویژگیهای اصلی دیتا کاتالوگ میتوان به موارد زیر اشاره کرد:
- شناسایی و کشف دادهها: جستوجو میان دادهها و منابع مختلف
- مدیریت متادیتا: ذخیرهی اطلاعاتی مانند نوع دادهها، فرمتها، ساختار و تاریخ تغییرات داده
- دسترسپذیری و همکاری: بهاشتراک گذاری دادهها برای همکاری بینتیمی سادهتر
S3 Data Catalog آروان یک دیتا کاتالوگ مدیریتشده بر پایهی Apache Iceberg است که بهطور مستقیم دادهها و متادیتای آنها را در داخل صندوقچههای فضای ابری ذخیره میکند. این سرویس یک رابط استاندارد Iceberg REST ارایه میدهد تا بتوانید از موتورهایی که پیشتر استفاده میکردید (مانند Spark و PyIceberg) به آن متصل شوید و از صندوقچههای خود مثل یک دیتابیس با ساختاری انعطافپذیر استفاده کنید.
دیتا کاتالوگ آروانکلاد به راحتی امکان تبدیل صندوقچههای فضای ابری را به یک انبار داده (Data Warehouse) برای انواع پردازشهای کاری تحلیلی از جمله تحلیل لاگها، هوش تجاری و پایپلای�نهای داده فراهم میکند.
Apache Iceberg چیست؟
Apache Iceberg یک فرمت جدول باز (Open Table Format) است که برای مدیریت دادههای تحلیلی با مقیاس بزرگ که در فضای ابری (Object Storage) ذخیره شدهاند طراحی شده است.
ویژگیهای کلیدی آن موارد زیر است:
- تراکنشهای ACID: اطمینان از خواندن و نوشتن همزمان و قابل اعتماد با یکپارچگی کامل دادهها.
- متادیتای بهینهشده: جلوگیری از اسکنهای کامل جدول با استفاده از متادیتای ایندکسشده برای اجرای سریعتر کوئریها.
- انعطافپذیری ساختار داده (Schema Evolution): امکان اضافه کردن، تغییر نام دادن و حذف ستونها بدون نیاز به بازنویسی دادهها.
Iceberg در حال حاضر بهطور گستردهای توسط موتورهایی مانند Apache Spark ،Trino ،Snowflake ،DuckDB و ClickHouse پشتیبانی میشود.
چرا به دیتا کاتالوگ نیاز دارید؟
اگرچه دیتا و متادیتای Iceberg بهطور مستقیم در فضای ابری ذخیره میشود، لیست جدولها و اشارهگرهای مربوط به متادیتای جاری باید بهشکل مرکزی توسط یک دیتا کاتالوگ مدیریت شوند.
بهطور مشابه، دیتا کاتالوگها با ایجاد دسترسی هماهنگ و منسجم این امکان را برای موتورهای جستوجو مختلف فراهم میکند تا بهطور ایمن از همان جدولها بخوانند و در آنها بنویسند بدون اینکه تداخلی در دادهها یا خرابی اطلاعات ایجاد شود.
فعالسازی دیتا کاتالوگ آروانکلاد
برای استفاده از دیتا کاتالوگ آروان، وارد پنل کاربری و بخش فضای ابری شوید. سپس روی قابلیت «دیتا کاتالوگ» کلیک کنید و در این صفحه، دکمهی «دیتا کاتالوگ» را بزنید.
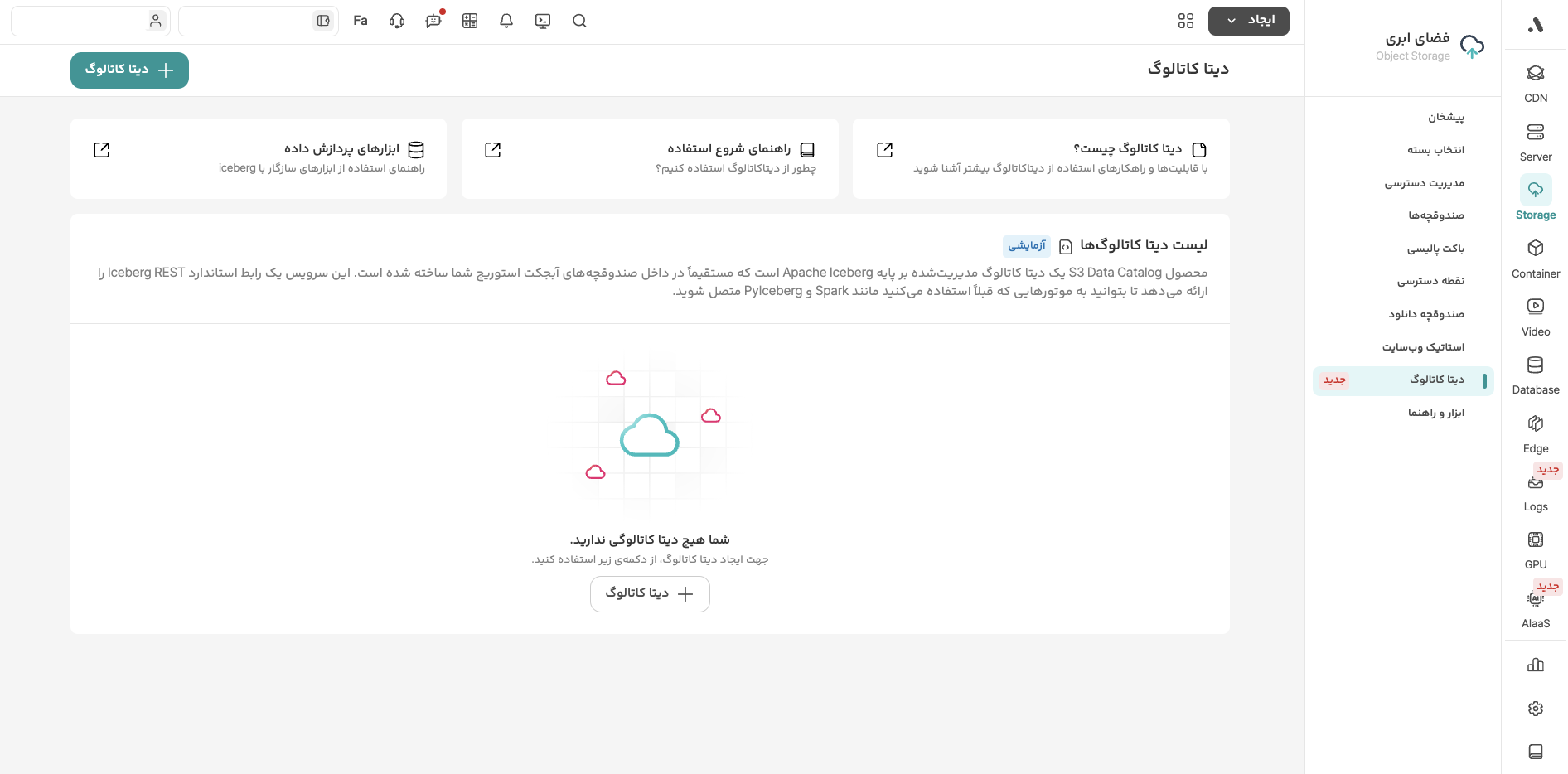
در صفحهی جدید، باید مشخصات دیتا کاتالوگ را وارد کنید.
ابتدا یک نام برای کاتالوگ تعیین کنید و سپس صندوقچهی آن را انتخاب کنید. اگر از پیش صندوقچهای ندارید، در همین صفحه میتوانید یک صندو�قچهی جدید بسازید. همچنین برای بخش کلیدهای دسترسی، باید حداقل یک کلید دسترسی ماشینیوزر ایجاد کرده باشید. راهنمای ماشینیوزر به شما در این مسیر کمک میکند.
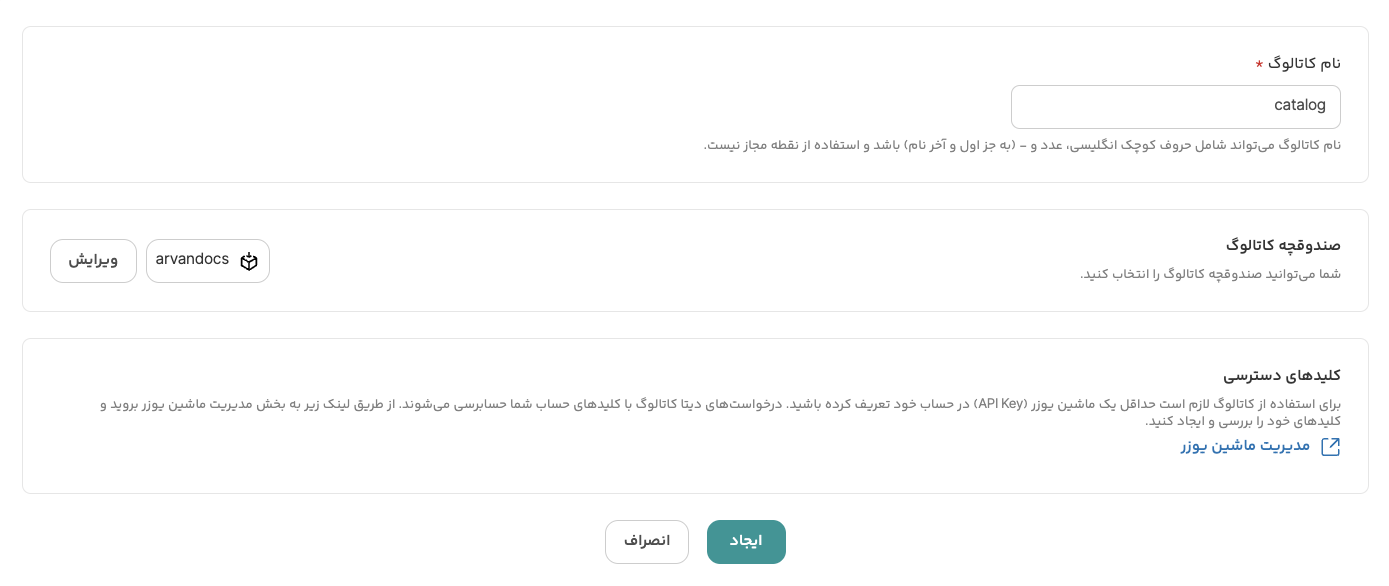
با کلیک روی دکمهی «ایجاد» کاتالوگ ساخته شده و میتوانید با استفاده از مقادیر Catalog URI ،Warehouse Name و کلید دسترسی خود ابزارهایتان را پیکربندی کنید.
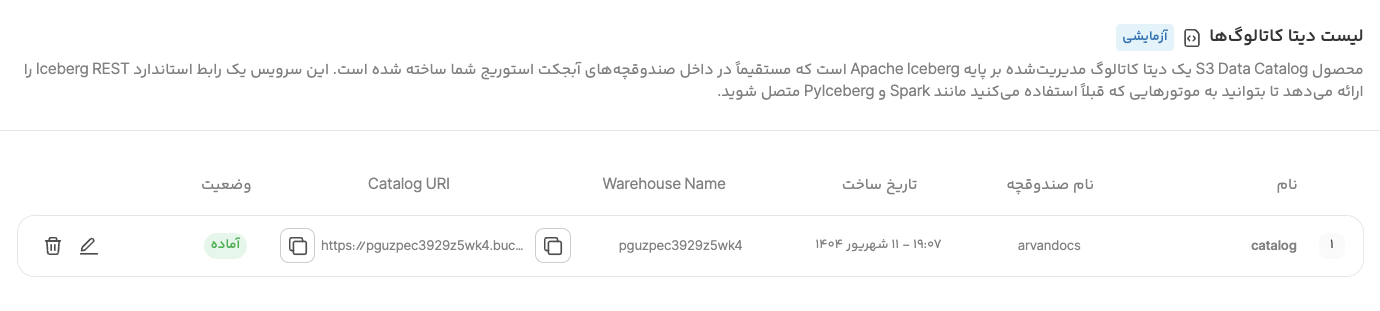
اکنون میتوانید با هر ابزاری که فرمت جدولباز را پشتیبانی کند از کاتالوگ استفاده کنید. مانند:
- PySpark
- PyIceberg
- DuckDB
- Trino
ابزارهای پردازش داده
از محبوبترین ابزارهای پردازش داده که میتوانید برای استفاده از دیتا کاتالوگ انتخاب کنید، PyIceberg و PySpark هستند.
استفاده از PyIceberg برای اتصال به دیتا کاتالوگ
پیش از شروع نیاز است کتابخانههای زیر را نصب کنید:
-
s3fs
-
PyIceberg
برای نصب از دستور زیر استفاده کنید:
pip install pyiceberg -
PyArrow
برای نصب از دستور زیر استفاده کنید:
pip install pyarrow
نمونه کد استفاده از PyIceberg
برای اتصال به دیتا کاتالوگ و ایجاد جدو�لهای Iceberg میتوانید از نمونهکد زیر استفاده کنید:
import pyarrow as pa
from pyiceberg.catalog.rest import RestCatalog
from pyiceberg.exceptions import NamespaceAlreadyExistsError, TableAlreadyExistsError
import string
import random
# Define catalog connection details
WAREHOUSE = "<WAREHOUSE_NAME>"
CATALOG_URI = "https://<WAREHOUSE_NAME>.bucketcatalog.arvanstorage.ir/iceberg/"
TOKEN = "apikey XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
ACCESS_KEY = "XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
SECRET_ACCESS_KEY = "XXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
# This configuration can be adjusted based on your needs. For large batch requests,
# if you encounter timeouts, you can increase the timeout values.
S3_CONNECT_TIMEOUT = "30"
S3_REQUEST_TIMEOUT = "30"
# Connect to ArvanCloud Data Catalog
catalog = RestCatalog(
name="my_catalog",
uri= CATALOG_URI,
warehouse= WAREHOUSE,
token=TOKEN,
**{
"s3.connect-timeout": S3_CONNECT_TIMEOUT,
"s3.request-timeout": S3_REQUEST_TIMEOUT,
"type": "rest",
"s3.access-key-id": ACCESS_KEY,
"s3.secret-access-key": SECRET_ACCESS_KEY
}
)
# Create arvan namespace if it doesn't exist
try:
catalog.create_namespace("arvan")
except NamespaceAlreadyExistsError:
pass
# Define table schema
schema = pa.schema([
("id", pa.int64()),
("name", pa.string())
])
# Create empty Iceberg table
test_table = ("arvan", "my_table")
try:
table = catalog.create_table(
test_table,
schema=schema,
)
except TableAlreadyExistsError:
table = catalog.load_table(test_table)
# Create PyArrow table with data
data = pa.table({
"id": [1, 2, 3, 4, 5],
"name": ["Rostam", "Sohrab", "Esfandiar", "Kaykhosrow", "Siyavash"],
})
# Write data to the table
with table.transaction() as txn:
txn.append(data)
# Load the existing Iceberg table
table = catalog.load_table(test_table)
# Read data from table with limit
result = table.scan(limit=10).to_arrow() # Removed row_filter=None
# Print results
print(result)
استفاده از PySpark برای اتصال به دیتا کاتالوگ
پیش از شروع نیاز است کتابخانههای زیر را نصب کنید:
-
Java 11
-
PySpark
برای نصب از دستور زیر استفاده کنید:
pip install pyspark==3.5.0
نمونه کد استفاده از PySpark
برای اتصال به دیتا کاتالوگ و اجرای کوئریها میتوانید از نمونهکد زیر استفاده کنید:
from pyspark.sql import SparkSession
import uuid
import time
import random
import string
import time
# Define catalog connection details
WAREHOUSE = "<WAREHOUSE_NAME>"
CATALOG_URI = "https://<WAREHOUSE_NAME>.bucketcatalog.arvanstorage.ir/iceberg/"
TOKEN = "apikey XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
# Initialize Spark session with Iceberg configurations
spark = SparkSession.builder \
.appName("IcebergDataCatalogExample") \
.config('spark.jars.packages',
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,'
'org.apache.iceberg:iceberg-aws-bundle:1.6.1') \
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.my_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.my_catalog.type", "rest") \
.config("spark.sql.catalog.my_catalog.uri", CATALOG_URI) \
.config("spark.sql.catalog.my_catalog.warehouse", WAREHOUSE) \
.config("spark.sql.catalog.my_catalog.token", TOKEN) \
.getOrCreate()
try:
# Step 1: Use catalog and create schema
print("Step 1: Creating schema")
spark.sql("USE my_catalog")
spark.sql(f"CREATE NAMESPACE IF NOT EXISTS default")
print("Available schemas:")
schemas = spark.sql("SHOW NAMESPACES IN my_catalog").collect()
for row in schemas:
print(f" - {row['namespace']}")
# Step 2: Create table
print("\nStep 2: Creating table")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS default.my_table (
id BIGINT,
name STRING
)
USING iceberg
""")
tables = spark.sql(f"SHOW TABLES IN default").collect()
print("Tables in schema:")
for row in tables:
print(f" - {row['tableName']}")
# Create a simple DataFrame
df = spark.createDataFrame(
[(1, "Rostam"), (2, "Sohrab"), (3, "Esfandiar"),(4, "Kaykhosrow"),(5, "Siyavash"),(6, "Faramarz")],
["id", "name"]
)
# Write the DataFrame to the Iceberg table
df.write \
.format("iceberg") \
.mode("append") \
.save("default.my_table")
# Read the data back from the Iceberg table
result_df = spark.read \
.format("iceberg") \
.load("default.my_table")
data_df = result_df.limit(5)
# Show the data
data = data_df.collect() # Collect the data from your DataFrame
for row in data:
# Print each row's data into the file
print(f"ID: {row['id']}, Name: {row['name']}\n")
except Exception as e:
print(f"Error occurred: {str(e)}")